解释结构模型方法(Interpretative Structural Modeling Method,简称ISM法)是一种用得很广的系统方法。上个论文下载网站就能搜出10来万相关的文章,本文认真的详细的分析了100篇近年发表的期刊论文,文中有原始矩阵,或者是有可达矩阵的,全部重新计算过。这样做想要达到的目的是:让读者更深入全面了解ISM方法,以及以往的一些论文有多少是错的,其比例有多少,并且知道错在哪个地方。
近年来随着化学加网提供稳定的服务器,目前用ISM方法写论文的一般都会用到本网站,一些是直接用本网站计算,另外一种是拿本网站进行结果比较与校验。100篇论文有一定的比例也是通过本程序计算而得出的结果。不过有几篇很遗憾,他们论文中的内容错了。错误的原因有两个:一种是把网上运算的结果弄到word中去,手一滑就错了。然后稀里糊涂的就发表了。另外一个比较典型的是货不对板,就是用的原因优先的分层方法获得的结果,她在文中说是用结果优先的方法抽取的。
通过与大量的论文作者深入交谈,我们一致得出一个结论:ISM方法是一个非常好的把写论文当成灌水的方法,是一个套路极强的写八股文一样的写作论文的方式。也就是其创新点,或者新意极少出现在ISM方法本身,更多的是分析的内容上。而目前选的100篇文章,都是老套的ISM方法,甚至是按照一些错误的教材上来的,教材都是错的,按照那种方法得来的大部分是错的。
在使用ISM基本上就如下几种形式:
1、单纯的用ISM方法。好一点的文章会把如何得到要素,要素之间的关系如何获得会有详细的交代。
2、用模糊解释结构模型的方法即FISM的方法。很遗憾目前运用FISM的方法基本是不全面的,或者说是脱下裤子放屁,多此一举。也可以说是错的。
3、DEMATEL方法与ISM方法联用。DEMATEL即:策试验和评价实验室方法,某种程度上可以把它看成是采用自然算子的模糊算子,也就是可以把它看成是FISM的一种,这种方法就是FISM的一种建模方法(使用特定的自然模糊算子,而非最大最小模糊算子)。而DEMATEL使用本身过程,要特别留意,无法求解的情况,即,无法求得逆矩阵的情况。也就是分母出现零值的过程,DEMATEL是无法计算下去的。
4、ISM与AHP(层次分析法)或者ANP(网络分析法)联用。大部分论文并没有交代为什么把这两个方法联用,两者的联系是在哪里?ISM能为ANP方法提供什么便利。否则是吃饱了撑的给论文凑字数?用ISM-AHP两种方法联用的,很多都是错的,错误率超过80%,因为都没有弄清楚什么是有向图,什么是无向图这个基本概念。AHP是一个典型的格式化的无向图,它关注的是权重,是基于三角关系对的一个矩阵。ISM与ANP联用的绝大部分是瞎掰,因为ANP的提出者弄了一个SD的软件,在初始化的时候有一个有向边的系统建构,那个箭头并不是图论中的有向边,而是强度的意思。用了ANP压根就没有必要用ISM。除非你说清楚ISM能给ANP提供什么支持!
写论文其最根本的本质是不能搞一个错的东西进行糊弄,离开了正确性一切都免谈。文章逼格的前提是不能是错的,如果计算都错的,整个文章就是一篇没有逼格的文章。
打算用ISM方法来写文章,首先要了解ISM方法的特点、原理与步骤。不过在讲这些之前,先来了解下ISM技术的历史。
ISM的概念是Linstone提出。ISM技术则由Warfield捣鼓出的,Warfield开始提出ISM就是用计算机来帮助文人研究复杂问题,用数学计算程序来解答问题。ISM方法不同于存粹的数理演算,更不完全属于社会科学范畴,它是介于自然科学与社会科学之间。从手法上来说,ISM建模需要矩阵运算或者是拓扑分析,这种是典型的数学或者系统科学的研究方法。但是将节点数字信息转化为具体的解释含义,这些分析过程都归属于社会科学的范围。因此,ISM 是一个特殊的,依靠自然科学的运算和社会科学的分析的方法,非常适合于自然科学和社会科学交叉类型的问题研究。
而如今,社会科学的研究者,经常被理工科的人喷,比如张嘴就来跑火车,拍脑袋就下结论之类,都是乱来。硕士博士写毕业论文就更惨了,答辩的时候经常被问的是,你的文章有什么创新点,你用的是什么研究方法。这个时候ISM是一种非常好的选择。对于这两个经典问题,如果你读懂了本文,这两个问题就不是问题了,尤其后面一个你用什么研究方法的问题。至于创新,你看完了本文,领悟要义对第一个问题,你也可以信心百倍的回答。
Warfield捣鼓出的ISM被人提及最多的是社会学科领域的作者。其实在计算机领域,就ISM方法本身,提出了个NP难题,这类问题一般是引起计算机界的科学家们前仆后继的去解决。有认真的手动绘制ISM最后的结果图人,只要你画出的层级图正确且简洁,漂亮,那么你就是比电脑厉害很多,你解决了一个世界级的难题。怎么才叫漂亮?那就是这个NP难题所对应的层级图边交叉数最小化问题。本网站部分解决了这个问题,那就是把拉动要素位置的权利交给了使用者,让使用者自己去拖动要素的位置,以减少带箭头的线段交叉的程度。而这类算法,就有人取过很好的名字,比如遗传算法,启发式算法,当然运用啥深度学习,有导师监督之类的都可以用上。
ISM是一种系统方法,其步骤如下:
通过观察上面用ISM方法得到的ISM步骤流程图,从层级上可以看出,ISM的步骤如下:
建立原始邻接矩阵是ISM方法的根基,是最重要的步骤,是整个ISM方法的根本。后续让离散数学差的的人仰望的一堆计算其实是一个体力活,它只是一个数理逻辑演算过程。而建立邻接矩阵的过程分为如下两步:
第一步、确定要素集
ISM是一个系统方法。解决复杂问题的原则就是复杂问题简单化!就确定系统要素集的原则来说,尽量只选择体现问题体系的核心要素。
而现在的文章有一些倾向,就是喜欢事无巨细的堆砌要素。把应当简化的事情复杂化。比如就有人请我帮计算有56个要素的矩阵。在后来的讨论中我开玩笑的说他是个神经病,来整一个56个民族56朵花的系统。最后他自己乖乖的把要素数目减少到15个!56个肯定不行,因为要素越多,越不能说清楚事物的本质。此外,他的文章是要发表的,排版这关就过不了。而把一些要素合并后,反而能更清晰的说明事物的本质,排版也更容易且更漂亮了。
事实上,简洁才是王道,复杂问题简单化才是解决事情的正道。具体到写论文,再具体到形成纸质的文章,它是有排版要求与字数限制的。通常来说系统的要素数目不要超过30个,一般来说小文章以10来个为佳。硕士论文或者博士论文可以适当的多一点,比如20来个要素。而只是概要性的说明问题,展示一个简单的概念,演示某个算法,7、8个就够了。
但是某些事物的确是复杂的,有很多要素构成,比如软件工程中有个CMM5的标准,其中就有快接近1000个的要素,没有看到哪个人整体介绍的时候会把几百个要素都丢上去。常见的就是合并出有限的10个,最后出个层次图来说明问题。
又比如公交换乘的计算,它就是一个ISM方法可以搞定的事,其站点有几千个,都是等价的,无法去掉这些要素。这种文章,重点就是方法了,没有必要把3000个站点加进去。
相关的论文显得有逼格,这一步的一般的格式来说是先罗列一堆要素,然后用简短的文字表达出如何剔除一些无关紧要的要素。这种行文方式,即能体现工作量,又能体现严谨的态度。
而提炼出核心要素的过程,可以使用一些常见的方法,比如主成份分析法,问卷统计等等,如果是基于客观事物的数据统计分析得到的核心要素则更佳。也有一些是常规、朴实的方法,但是这些方法体现到文章中,会使得文章更有逼格,比如本网站有一个用5W1H的方法获得关键要素的例子。
学管理,或者经济学、以及搞传销的这类方法就更多了,比如麦肯锡七步法;5W2H法,就是在how方法后加个how much; 6W2H,就是多加个which;5M1E法;8D方法;SMART方法;波特5力分析;标杆分析法……
第二步、两两比较要素之间的二元关系并建立邻接布尔矩阵
ISM方法中建立邻接矩阵是通过要素两两比较判断得到。其中要素$S_i$ 跟要素$S_j$ 要比较两次,分别是要素$S_i$ 对要素$S_j$ 的直接影响;要素$S_j$ 对要素$S_i$ 的直接影响。对于整个系统来说存在n个要素则要比较n(n-1)次。而要素自身则不需要比较,即矩阵的对角线上的值通常用0来表示。
以56个民族56朵花的那个哥们的例子来说。他建立的那个矩阵,需要进行${56 \times 55}$ 即3080次比较。这个数太大了,显然不大现实。
通常定义原始矩阵为$A$,$A$中的值用${a_{ij}}$表示。$A={(a_{ij})_{n \times n}}$
$$ a_{ij}= \begin{cases} 0, \text{ $S_i$}\rightarrow \text{$S_j$ 不存在直接二元关系} \\ 1, \text{ $S_i$}\rightarrow \text{$S_j$ 存在直接二元关系} \end{cases} $$有上述定义可以看出,ISM中的原始矩阵为$A$ 是一个方阵。而这个方阵中行与列代表同一个要素。
在建立邻接矩阵$A$ 中存在着一个难点。就是要素$S_i$ 对要素$S_j$即的直接二元关系存在着模糊性,${a_{ij}}$到底是取0,还是取1谁都没有把握,非工程类的抽象系统,这个东西就不好扯得清楚了。所以有所谓的ISM专家小组,或者德尔菲法(Delphi method),或者是问卷走走形式。在文中一定要提一下。实际上大家都明白,尤其是管理类的,这些都是瞎扯的一些数据而已,或者是拍脑袋想当然而已。但是即便如此对于某些没有把握的值能交代自己是如何拍脑袋的过程,比走形式写上什么ISM砖家小组的套话,更有说服力。
如果作者能聚焦${a_{ij}}$的不确定性,即可能是真,可能是否,也可能是0或者1之间的值,那这篇文章就有新意多了,也就可以引申出新的方法,然后自己可以给这种方法取一些高大上的名字,只要合理可以使劲的吹。 对于这种矩阵就不是布尔矩阵了,由于不确定性的引入,可以演变成无数种形式。研究比较多点的叫模糊矩阵。模糊矩阵其实就是${a_{ij}}$取值为0到1之间的值而已。对应的方法叫模糊解释结构模型即FISM。
不确定性矩阵中取值描述如下:
$$ a_{ij}= \begin{cases} 0 , \text{ $S_i$}\rightarrow \text{$S_j$ 不存在直接二元关系} \\ U , \text{ $S_i$}\rightarrow \text{$S_j$ 不确定直接二元关系U取0或者1} \\ 1, \text{ $S_i$}\rightarrow \text{$S_j$ 存在直接二元关系} \end{cases} $$而其它的建模则,可以花样翻新,自己根据需要取名字。比如薛定谔的猫矩阵,量子矩阵,甚至量子纠缠,以及化学里的共轭关系,共振体关系都是这种的表达方式的一个具体化。事实上人工智能的基础,即神经网络,本质就是一堆矩阵的运算。
常有人问我,“我数学是个白痴,你讲的矩阵我完全不懂,怎样才能整出新意?”对于这类问题,一般就推荐在不确定的值里找亮点,也就是说你负责取好名字,我负责计算的正确性。
计算可达矩阵并非必须的步骤,只不过书上都这么说,并且后续的内容都可以通过可达矩阵求解得到。所以给大家的印象是可达矩阵的求解是一个必要的过程。
对于一个要素相对比较多的系统,比如超过20个要素的系统,现在几乎没有谁去手算。说句不好听的,谁手算谁SB。聪明的方法是,尽量合并要素,弄到10个左右,或者是编个小程序,或者请人编个小程序计算一下。大部分是用matlab编一下,就10来行代码的样子。
抛开ISM单纯的讲可达过程,它非常有用,比如公交换乘系统,利用可达矩阵的话,可以让计算换乘次数的最优解,瞬间出来,因为其本质是已经先算过一遍,后续的只是简单的查找而已。此外,在诸如处理分子结构图的时候可以用可达矩阵求解的方法去标定分子结构的拓扑唯一序。
如果只是运用ISM方法的论文,无需讲可达矩阵运算的具体过程。但是作者应该大体了解有几种算法,那种算法最高效。
~ |
计算方式 |
使用情况 |
| 连乘法 |
原始矩阵$\color{blue}{A}$加单位矩阵$I$,即对角线都加上1得到相乘矩阵$B$。 对相乘矩阵连乘直到矩阵不发生变化时候,即得到可达矩阵$R$。 $$(A+I)^{(k-1)}≠(A+I)^{k}=(A+I)^{(k+1)}=R$$ $$即:B^{(k-1)}≠B^{k}=B^{(k+1)}=R$$ |
该方法,数学表达式简单,好理解。 通常计算都是用这种方法,大部分教科书也是用的这种方法。 缺点:运算慢。 |
| 幂乘法 | $$(A+I)→(A+I)^{(2)}→(A+I)^{(2).(2)}→(A+I)^{(2).(2).(2) }→⋯→(A+I)^{(2k)}$$ | 运用ISM类的文章,只有偶尔几篇提及此方法 对于特定的邻接矩阵,该方法通常比连乘法稍微快一点点,快不了太多 |
| Warshall法 |
warshall 算法又叫传递闭包,计算机专业的有讲这个,离散数学也有讲到这个算法,这是一个经典算法。 对$B \mapsto B=\mathscr{T}B $ 其意思为:由矩阵$B$对矩阵$B$进行传递闭包,得到转移矩阵,记作:$\mathscr{T}B $ 接着不停的进行warshall 操作直到转移矩阵相同即可 $\mathscr{T}B \mapsto B=\mathscr{TT}B $ 从形式上看,warshall法跟连乘法是一样的,只不过把布尔矩阵中的矩阵乘法变成了求转移矩阵的方法。 |
有部分研究ISM算法的论文有提及该算法。 优点:运算速度中等。 缺点:稍微有点难理解! |
| 改进的迭代Warshall法 |
对每个要素进行warshall操作后,记录其状态,下个要素迭代时候是以当前状态为基础进行迭代! |
优点:运算速度中等。 缺点:稍微有点难理解! |
| 一次性Warshall法 | 通过tarjan算法根据原始矩阵求出所有的强连通分量 由上述强连通分量的顺序对原始矩阵进行等价变换得到新的矩阵,该矩阵是一个下三角形式的布尔矩阵 从上到下,进行一次Warshall运算就得到了可达矩阵。 |
优点:运算速度得到数量级的提高,是吓死人的快。矩阵越大,其效率比矩阵连乘法方法快100倍以上! 缺点:难理解! 如果是专门研究ISM方法的人,就这个计算过程可以重点写。 Tarjan是个大牛人,因为他1986年获得了有计算机界诺贝尔奖的图灵奖。 这个求强连通分量的算法就是一次性walshall求可达矩阵的前提。 但是两个算法联合求可达矩阵我目前还没有看到相关的文献。 |
总之,对于普通的写文章的人来说,只要知道第一种方法就行了,现在工具这么多的时代,谁还手算呀!对于在论文中是否贴上可达矩阵,取决与实际计算的过程,如果后续的过程没有用到,可以不贴出可达矩阵,如果用到了且版面允许,可达矩阵必须写出。这个是证明是否计算正确的一个重要标准。如果版面限制,可达矩阵可以简要的用一个略字表达。如果是硕士或者博士论文,可达矩阵是关键过程,必须贴。如果没有贴,这篇论文大概率是瞎掰的论文。
ISM方法中四大运算为:区域划分运算,缩点运算,缩边运算,层级划分运算。在讲ISM的四大核心运算之前,先来看几乎90%的论文与教材实际采用跟介绍的ISM方法的过程。
比较详细的ISM步骤如下:
上面的层次图,把区域分解,也就是判断图的连通性,当成了一个次要的要素,给丢掉了。而把缩边与缩点放到了一起为了介绍一个求骨架矩阵的代数公式。
$$S=R-(R-I)^2$$
大部分论文与书籍介绍的如下:
这种编排也很合理,它体现复杂的事情简单化的原则,说明了ISM方法干的事就是给出一个有依据的层级图。而它的规则就是结果优先抽取规则。缩边与缩点不是核心要素,也就是有没有这个东西没有并不影响我主要想表达的东西,即:用ISM方法的核心是得到一个层级划分的网络图。
而笔者一般推荐如下的步骤:
第一大运算:区域划分
区域划分就是连通性计算。也就是算出矩阵分为几块互不连通的区域。笔者喜欢把这个计算叫系统数目的判定。在系统科学里是这么界定系统的:系统是要素与要素之间有机的联系在一起。如果没有联系在一起,就不叫系统了。
但是这步计算绝对不能叫子系统计算。因为一个大的系统里其子系统是会跟其它的要素或者子系统发生联系的。
上图就包含两个系统。系统1含有的要素是{兔、龙、羊、马、蛇};系统2包含的要素是{鼠、牛、虎}
为什么大部分论文都不能体现判断有多少个系统这一步呢?
第一、因为运用ISM方法的一般都是分析一个系统的。出现不连通的情况相对很少。
第二、即便出现几个系统的情况,也不影响分层的结果。因为四大运算是并立的,分别的运算。
有一些人可能郁闷了,我明明就是分析得没有错,怎么画出来的就有几大块呢?这种情况该怎么处理?
笔者印象比较深的是帮人弄的几个分析都出现过几大块的情况。
如何买到自己心仪的汽车?
如何买到自己心仪的房子?
选择哪个人做女朋友?
我是应该在大城市工作还是回老家工作?
上述几个问题,都是先列出一堆要素,然后根据要素之间的列出原始布尔矩阵,最后得到层级。然后根据层级用ANP模型或者是AHP模型,根据当事人的自己的感觉或者决定,最后下最终决定。
而上述情况都出现了几大块区域的情况。而要解决这个问题,其实很简单,就是加上一个总要素就成了,即总目标。
$$ 原矩阵M1=\begin{array} {c|c|c|c|cccc} {M_{4 \times 4}} &A & B & C &D \\ \hline A & 0 & 0 & 0 & 0 \\ \hline B & 0 & 0 & 1 & 1 \\ \hline C & 0 & 1 & 0 & 1 \\ \hline D & 0 & 1 & 1 & 0 \end{array} $$
$$ 矩阵M2=\begin{array} {c|ccccccc} \color{red}{M_{5 \times 5}} &A & B & C &D & Z\\ \hline A & 0 & 0 & 0 & 0 & 1 \\ \hline B & 0 & 0 & 1 & 1 & 1 \\ \hline C & 0 & 1 & 0 & 1 & 1 \\ \hline D & 0 & 1 & 1 & 0 & 1 \\ \hline Z & 0 & 0 & 0 & 0 & 0 \\ \end{array} \\ (Z为总目标要素) $$
总目标要素的特点从矩阵上可以看出,一般放到第一个或者放到最后,方便程序计算。目前比较流行的套路是放到第一个,还取名通常是S0。该要素的特征是行的值都为0(包括自身到自身由于定义的问题所以取0),其列的值都为1。图形上的特征是在最上层,所有的要素都发箭头指向它。
第二大运算:缩点
所谓缩点运算,就是把一个回路当成一个要素处理。也就是把形成回路的多个节点当一个节点处理。用数学语言来定义回路即是:包含有两个或者两个以上要素的强连通分量。
回路不要说成环路,回路跟环路是有本质的不同,回路是针对有向图而言,环路是针对无向图而言。比如 ${A→B}, {B→C}, {A→C}$ 一个系统是环路但不是回路。
不过对于有向图来说,因为翻译的问题,大家都习惯了环路这个说法,也就是对于有向图来说,上面的两个箭头指向同一个要素形成的环路,不叫环路了。只把回路叫成环路。这种习惯叫法就好比水比油重,但是这个重显然不是指质量与重量,而是指密度更大的意思。
回路又叫反馈系统,一个系统里出现多个回路,每个回路就是一个反馈子系统。
在其它结构模型中,回路的研究是一个非常重要的内容,甚至是最重要的内容。但是在ISM中,它并不是最重要的内容,毕竟有很多论文中压根就没有回路。
回路在ISM最终层级图中最大的特点是:回路中的要素处于同一层级!
涉及到反馈系统中的箭头,分为三大类:
输入:即从别的要素发出到回路要素中的箭头,在解释结构模型中,一般是弄成下层集的要素发出,回路中的要素接收。
输出:即从回路要素中发出的箭头。在ISM层级图中 回路是处于下层级,接收箭头的是上层级的要素。
反馈:一个回路中的其真实的反馈可能很复杂,通常用一个简单的回路代替。而要计算真实的回路时间复杂度很高,即可以简化成一笔画的问题。
如上图所示:系统(A,B,C)并不存在一条简单的回路。要一笔画的话它只有一个螺环回路$A→B→C→B→A$。但是这种回路通常用$A→B→C→A$一个简单回路代替。
有很多人用本网站计算后,发现最后的结果是挤成了一坨。比如,有的是18个要素结果缩成了3个节点两层,尤其是一些管理类的文章。
其实这种结果很正常,是常态。因为很多系统本身是一个反馈系统,比如传播体系,就是之间来回折腾的一个大反馈系统,要图形漂亮就是把一个弱关系,变成零。这个也是ISM小组要干的事。如果你能把这个特定的值记下会给文章增色不少。这里再次强调下,ISM方法的根本是第一步,即建立邻接矩阵的步骤!
总之,在ISM中不管你缩点还是不缩点,一定要记住的是:同一个回路的要素必定处于同一层!这个特点是瞄一眼文章就知道这个作者是不是瞎掰的。比如有不少文章,在层级图中出现了同一层级有箭头,且不是在回路中。这样的文章肯定是错的。
求回路的方法,其本质就是求强连通分量。目前有三大经典的算法。都是双指针方式的变种。在Kosaraju(克鲁斯克尔),Tarjan(塔杨),Gabow(家伯)三大算法中。Tarjan算法值得写上一下,该算法的发现者,由于在处理回路的塔杨算法获得了图灵奖。
第三大运算:缩边
缩边运算其本质是把重复的路径删除,即把所有的向前边删除。
比如一个无回路的系统由$(A,B,C)$组成;路径有${A→B}, {B→C}, {A→C}$ 从$A跟C$可达的角度考虑存在着$(A→B→C) ,(A→C)$两条路径。其中$(A→C)$是可以删除的。也就是存在着多条可达路径,最短的那条路径是可以删除的。在现实世界中缩边的原则是经常出现的。比如不要越级指挥。
在一个系统里找到所有的向前边是一件麻烦事。但是对于没有回路的矩阵来说,即DAG,算出所有可以缩掉的边后的矩阵有一个简单的代数表达形式。
$S=R-(R-I)^2$
不过,该计算,算术表达虽然简单,实际运算起来的时间复杂度并不低,因为用到了矩阵的乘法!有更低的方法是直接求交集的方法,该方法要快一些。
上述公式中$S$为缩减矩阵,并且只有可达矩阵$R$中不存在回路才成立。该公式其实就是求缩边,并非缩点。当系统为DAG时候,该缩减矩阵中边的总数最少,且矩阵为唯一。该唯一的缩边缩减矩阵叫骨架矩阵!
缩边与缩点是紧密联系在一起的。有缩点一定存在缩边!
此外对于存在回路,如何获得代表性的缩边矩阵!主要从反馈系统的性质说起。上面介绍过了跟回路中相关的箭头分为三类,输入,输出,反馈。
对于存在回路的缩边,通常用三种方法进行,本人推荐最后一种。具体方式如下:
大部分文章都会有缩边的。不过这步错的人特别多。主要是折腾出了层级分布,然后一个个加线的时候,有很多人是先把原始矩阵复原后,手动减少线段,要素一多,错误就不可避免。
另外一个错误是,没有判断有没有回路,就直接套用$S=R-(R-I)^2$公式,然后把$S$套回去,这样就错得乱七八糟的。
第四大运算:层级划分
在讲ISM方法的时候之所以要讲可达矩阵,就是因为经典的ISM方法中进行层次划分的时候要用到可达矩阵。在讲层次划分的若干方法前先要了解三个集合的概念:
可达集合,先行集合,共同集合
$$ 可达矩阵R=\begin{array} {c|ccccccc}{M_{11 \times11}} &S1 &S2 &S3 &S4 &S5 &S6 &S7 &S8 &S9 &S10 &S11\\ \hline S1 &1 &1 &1 &1 &1 &1 &1 &1 &0 &0 &0\\ \hline S2 &1 &1 &1 &1 &1 &1 &1 &1 &0 &0 &0\\ \hline S3 &1 &1 &1 &1 &1 &1 &1 &1 &0 &0 &0\\ \hline S4 &1 &1 &1 &1 &1 &1 &1 &1 &0 &0 &0\\ \hline S5 &1 &1 &1 &1 &1 &1 &1 &1 &0 &0 &0\\ \hline S6 &1 &1 &1 &1 &1 &1 &1 &1 &0 &0 &0\\ \hline S7 &1 &1 &1 &1 &1 &1 &1 &1 &0 &0 &0\\ \hline S8 &1 &1 &1 &1 &1 &1 &1 &1 &0 &0 &0\\ \hline S9 &1 &1 &1 &1 &1 &1 &1 &1 &1 &0 &0\\ \hline S10 &1 &1 &1 &1 &1 &1 &1 &1 &0 &1 &0\\ \hline S11 &1 &1 &1 &1 &1 &1 &1 &1 &1 &1 &1\\ \hline \end{array} $$在可达矩阵$R$中其要素$S1$的可达集合记作$R(S1)$。$R(S1)=\{S1,S2,S3,S4,S5,S6,S7,S8\}$ 观察可达矩阵知道该值为S1要素所在行,对应的要素。
在可达矩阵$R$中其要素$S1$的先行集合记作$Q(S1)$。$Q(S1)=\{S1,S2,S3,S4,S5,S6,S7,S8,S9,S10,S11\}$ 观察可达矩阵知道该值为S1要素所在列,对应的要素。
在可达矩阵$R$中其要素$S1$的共同集合记作$T(S1)$。$T(S1)=R(S1)\cap Q(S1) $ 即 $T(S1)=\{S1,S2,S3,S4,S5,S6,S7,S8\}$
从图形样式上看,不管哪种抽取规则,ISM的层级结构都有如下特征:
除了回路的箭头外,所有箭头朝向一致,通常是用向上来表示!
回路中的要素,必定处于同一层级!
在符合上述规则的前提下,ISM抽取出来的层级数目最少!
层次划分是ISM最核心的运算。其它的可以不讲,包括可达矩阵的求解,但是层次划分一定要有。而层次划分分为如下四大类,而其中的三大类都跟三种集合相关,尤其是共同集等于先行集,共同集等于结果集的意义。
第一大类:结果优先的层级抽取规则方法:$ T(e_i)=R(e_i) $
这个是及其套路的方法,99%的用ISM方法的论文都是用这个经典的方法。也可以说是毫无新意的方法了。这种方法的本质就是先把系统中最终结果的要素抽取出来放到最上面一层。然后以此类推的抽取。
这种结果优先的层级抽取方法出来的层级图还有一个特征。
除了ISM层级图的三特征外,要素尽量放置在最上面的层级。
从物理学角度考虑,即重力势能最大。外形上看部分要素是上吊一样,悬着。头重脚轻。
第二大类:原因优先的层级抽取规则方法:$T(e_i)=Q(e_i)$
这个我吹下牛,原因优先的抽取抽取方法不敢说我是第一个发现这个方法的,但是绝对是独立发现这个方法的。来源其实简单,写程序弄反一下测试下结果。从逻辑上来看,结果优先抽取是原命题的话,原因优先是逆命题。而后面两种抽取规则应该是我提出的。原因优先的抽取规则的本质就是先把系统中根本原因的要素抽取出来放到最下面一层。然后以此类推的抽取。
这种原因优先的层级抽取方法出来的层级图还有一个特征。
除了ISM层级图三特征外,要素尽量放置在最下面的层级。
从物理学角度考虑,即重力势能最小。外形上看,就是底盘低,沉稳。
第三大类:轮换抽取规则
而这种轮换抽取规则,又分为两种
第一种:结果优先-原因优先轮换
即:第一次用,$T(e_i )=R(e_i)$ 第二次用$T(e_i )=Q(e_i)$ 其中结果优先抽取出的要素放置上层;原因优先抽取出的要素放置于下层。
第二种:原因优先-结果优先轮换
即:第一次用$T(e_i )=Q(e_i)$, 第二次用 $T(e_i )=R(e_i)$其中结果优先抽取出的要素放置上层;原因优先抽取出的要素放置于下层。
轮换法来的层级图特有情况是。
除了ISM层级图三特征外,要素尽量放置在最上面与最下面的层级。即结果的要素尽量在上层,原因的要素尽量在下层。或者说输入尽量放下层,输出尽量放上层.
从物理学角度考虑,即弹性势能能最大。外形上看,就是拉得最开的弹簧。或者说哑铃,立着的哑铃型!
第四大类:活动要素分解递归还原
这个的算法很复杂,跟上面的三个集合概念没有直接关联。它是先求出活动要素与非活动要素,非活动要素先弄好层级图;然后根据活动要素的情况,分块拼接。我曾经测试构造过2000个要素无回路矩阵,然后拼接其最紧凑的层级图。
从物理学角度考虑,即弹性势能能最小。外形上看,就是两端向中间收缩形的。即纺锤型,立着的纺锤!
就文章的角度而言,ISM层级图建构是最重要的,前面辛辛苦苦那么多,说明啥问题,解答啥问题,得出的结论就是靠这张层级图。如果后续还有更重要的计算或者解释,且版面有限制,原始矩阵,可达矩阵,层级划分,全部可以用略字表达。单独这张图不能少。
跟前面的电脑干的活一样,ISM层级图建构要好看,要有逼格,首先是要对的!那什么叫对的呢?如何快速的判断ISM层级图的对错呢?
快速的判断ISM层级图的对错有如下几点!
◎ 有没有平行走向的箭头
似乎是约定俗成了,ISM方法都是用箭头朝上的指示方法!这个跟大多数人的认知习惯吻合,也就是习惯把原因放下面,然后导致上面的结果要素。如果有平行走向的箭头,它一定属于某个回路!
◎ 不得减掉缩边(骨架)矩阵中的任何一个箭头,不得加上任何一条可达矩阵中不存在的箭头
始邻接矩阵$A$,可达矩阵$R$,骨架矩阵(包括一般性骨架矩阵)$S$三者的关系是:${S}\subseteq {A}\subseteq {R}$。如果去掉了缩边矩阵中的一个值,就不是等可达结构了。可达矩阵上添上一个值也不是等可达结构了。增加了一条可达矩阵中不存在的边,也是变成了另外一种结构的矩阵了。
系统方法的一大精髓,就是复杂的事情简单化,层次化,按照ISM的原理,层级出来后,往回套画箭头指向的时候,省事的做法是代入原始矩阵,但是这样显得很臃肿;通常是代入一般性骨架矩阵(1)即保留回路要素的缩边骨架矩阵,缩边算法是随便用一个简单的回路表示,而用一个要素作为回路的输入与输出入口就可以了。而错误的层级图比较突出的问题是回路的表达,另外一个是容易删除不能删除的跨层级的箭头!
◎ 层次里的要素跟行文不能货不对板
有几个作者用本站的程序运算得出结果后,然后顺利的把文章发表了。然后他们把文章拿给我看,我一看就指出来了,他们的文章叫货不对板。文中讲原理是搬教科书上的层级抽取方法过来,即结果优先的抽取方法,而实际在本网站上运算的是原因优先的抽取方法。这种是最典型的货不对板。
这三个判断中,第一个和第三个特别容易,扫一眼层级图就能看出来,后一个就需要耐心一点。
层级图要对的这个是基本条件。没有什么好讲的。只要是对的,它一定有层次感!但是应该清楚,除了正确之外还需要漂亮。漂亮这个东西不好界定。量化起来就更难,就ISM的层级图来说,有如下三点值得说一下。
◎ 回路的画法
回路怎么画,取决于实际需要,如果是真实的实体类的,比如线路板布线,这种要素是不能少的,也就是缩点,缩边都不行。对于这种代入的一定要是原始矩阵,而回路用个虚框框柱。下层级进来的箭头,到虚框的一个固定点即可。回路里的箭头要原本的根据原始矩阵中的关系画出。
如果是示意,不想缩点。处理方法是:回路用个虚框框柱。回路各个平铺开来,间隔的要素之间用一个双向箭头即可。如同这篇里的一样!
此外可以完全不理会回路之间的线路走向。直接把回路的要素放到一个框里,用一个节点表示就可以,或者是把要素堆叠在一起。
◎ 线的交叉最少
线少,线的交叉节点自然就少了。基于美观的原因,所以层级确定后,迭代回去用缩边矩阵就好很多。
选用中间收缩型的分层方法,线的交叉会少。实际绘制层级图的时候跟数学的规约计算是不同的。数学上的或者说拓扑结构上的点是没有尺寸的,它不是立体或者平面几何意义上的要素节点。因此跨层的线段越容易出现交叉,而这个交叉不是说跟线的交叉,还有线跟元素区块的交叉。中间收缩型的分层方法,即是第四种,由于跨层级的箭头线少,线与线出现交叉的几率也少,线与要素块出现的交叉的概率也少。
同一层级的要素多拖拽拉动一下,从效果上瞅一眼,感觉好的,就是交叉少的。这就是我做的这个运算程序比较吸引人且受欢迎的地方。而且我发现有一些人真的很懒,不知道如何去移动一下,所以特意把有大回路的层级,并没有去分开。比如$\{1,4,5\},\{2,3,6\}$两个回路,我可以按照$\{1,2,3,4,5,6\}$排列。这样就团成一团。对程序来说其实并不省事的。这样做就是为了让使用者去拖动一下,并体验一下这个算法。事实上,绘制可以拖动的这种层级图是程序上的工作量最大。
◎ 黄金分割比例
黄金分割是个经常被灌输的一个概念,比如美女的身材好,有大长腿是一个加分项,有人弄出了腰部以下,跟腰部以上长度的比是符合黄金比例的。绘制层级图的时候,有个搞艺术的人就跟我讨论到,我的程序中,元素块的高度,跟直线包含箭头的长度,大致按照1:1的比例,或者箭头长度再长一点用黄金分割的比例,就好看很多。此外我的箭头线条模式可以用回直线,而不用贝塞尔曲线。我自己手动弄了一下的确会好看很多。不过也仅限手动调整,真要算的话,那是很麻烦的事。因为每个要素上的字数就不同,有一些存在换行,不换行的话,要素块之间会重叠。在网页上搞一个能改变要素块大小的东西就很麻烦。
上面的黄金分割比例仅仅是从高的角度来考虑,按照这种说法,有部分层级图怎么也漂亮不起来,一看就是个矮胖子,因为某个回路有很多要素,放一起,宽都不够放。我写程序就深有体会,真的给一个大矩阵每个值按照0.5的概率给一个1的值,基本上出来的就是一个点,团成一团。这种情况有两种办法,一种是从长度考虑黄金分割比例,另外一种就是弄个亚层,把有回路的级间距离弄大。这样就好看多了。
前面提到,硕士博士论文答辩的时候,老师经常会问,你的论文有什么创新。有个用ISM的人跟我讨论说:“每当听到老板们说这句话的时候,我心中有一万头草泥马奔腾而过,我连布尔矩阵怎么乘都算不出,你还叫我创新。我只是要求平平安安的过了答辩,别出错就行,你还叫我创新……”
当时听了感慨万千,倒不是说老师们强调创新,这个是老板们通常的调调,几乎是通用的,尤其是涉及到交叉学科,老板们基本都这么问。而是那个基本的问题,布尔矩阵相乘得到的结果是啥的问题。其实我相信超过一半以上的人都不一定记得。包括我,虽然经常有人来问我。当年我第一次接触ISM的时候,由于老师讲得很好,所以后面的步骤觉得都简单得要死,就是矩阵相乘的地方烦得要死,也不明白,而老师可能觉得这个是最简单的基础知识,反而没有讲,一笔带过,所以我最不明白的是布尔矩阵怎么相乘的。到后来手算的话,10次我有9次都是算错的,最后逼得没有办法,让电脑算。
$$\begin{vmatrix} 1&0&1&1\\ 0&1&0&1\\ 0&0&1&0\\ 0&1&1&1\\ \end{vmatrix}\times \begin{vmatrix}1&1&1&1\\ 0&1&1&1\\ 0&0&1&0\\ 0&1&1&1\\\end{vmatrix}=\begin{pmatrix}1&1&1&1\\ \color{red}{?}&1&1&1\\ 0&0&1&0\\ 0&\color{red}{?}&\color{red}{?}&\color{red}{?}\\\end{pmatrix}$$比如上面的乘法中问号部分哪怕是现在我一下子也不知道怎么算,要去看下公式。
$$\begin{equation}\begin{split} c_{21}&=\sum_{k=1}^4 a_{2k}\times b_{k1} \\ &=a_{21}\times b_{11} + a_{22}\times b_{21}+a_{23}\times b_{31}+a_{24}\times b_{41}\\ &=0\times 1 + 1\times0+0\times 0+1\times 0 \\ &=0 \end{split}\end{equation}$$上面是第二行第一列的值算的过程。如果是用matlab编程的,他更不容易记住这个基本步骤,因为matlab就一个函数搞定。事实上函数重头写到尾的也很容易把行与列搞反,反正我就经常搞反,10次有9次都弄错,但是并不妨碍我拿矩阵运算去吹牛。
那回过头来,用ISM方法有啥创新的的呢?由于接触用ISM的多,这块我就说下自己的看法。我认为大致有如下几个方面。
ISM是老早老早出现的东西了,算很成熟的方法,各学科的教材都有介绍这种方法。既然是成熟的研究方法,那它就必然形成了其套路。而根据前面讲的,ISM最根本,最核心的是建立邻接矩阵这一步。也就是用ISM方法只要你不是研究这个方法论本身,新意是体现在第一步即如何建立原始矩阵的。算的过程有啥好讲的,交给一个工匠就行。或者找个懂点电脑的本科生,让他去编程就行了。或者丢给本网站的程序,让它去算就行了。而这一步根本不涉及布尔矩阵怎么相乘。所以不影响研究内容上有新意。
那什么研究内容才有新意,术业有专攻,具体的学科上的我答不上来。不过有两个人交解释结构模型的作业,让我印象非常深刻。这两个作业就是跟知名机构与有名的现象互喷,互怼。
第一个怼的好像是一个联合国的机构。那个机构发布了一个报告,就是给各国的人排一个幸福指数。最后给的结果是,战火纷飞的叙利亚,其人民的幸福感要高于我大天朝。这显然是胡扯呀。
然后这个小菇娘的作业就是要怼这个机构的专家。而她发现,人家专家也是有研究方法的,也有调研数据的。也有信度分布区间的。她的角度就是从研究方法的角度考虑,也就是先找出幸福感有什么要素组成,其层次分布如何。最后的意思就是你给一个要饿死的人一口饭,他的幸福感,跟你完成了飞天时候的幸福感是不同层次的。也就是那个研究幸福感的专家研究方法都错了,逻辑关系都是混乱的,你只要多采访几个死了亲人的,你去问问他们的幸福感,而不是去采访逃出来且被收留的难民!
第二个怼的是一个知名的段子。有个研究人员,研究螃蟹的耳朵在哪里,他设计的实验为:先拍拍手,发现螃蟹会逃跑。接着它把螃蟹的腿裹住,然后拍拍手,发现螃蟹不会跑。最后得出结论,螃蟹的听力器官在腿上。事实上螃蟹的听力器官的确是在螃蟹的腿上。那么如何用ISM方法来说明这个实验并不严谨。最后这个哥们用了几个要素,然后从逻辑关系上把这个东西讲清楚了。
与两篇类似,我还碰到过一个要素数目只有两个的用ISM方法来解答问题的。他研究的内容叫本拉登与塔利班头目奥马尔关系的研究。这个有点搞笑的研究,但是从方法的角度值得学习。他把两者的关系分了好几类,其中有两类一个是亲属关系,一个是事业上的。然后把每个维度都变成了一个邻接矩阵。比如亲属关系。由于拉登娶了奥马尔的女儿,所以拉登是奥马尔的长辈。同时奥马尔又娶了拉登的女儿,所以奥马尔是拉登的长辈。
$$ 亲属维度的原始矩阵A=\begin{array} {c|c|c|c}{M_{2 \times2}} &拉登 &奥马尔 \\ \hline 拉登 &0 &1 \\ \hline 奥马尔 &1 &0 \\ \hline \end{array} $$同样的其它维度可以给出一个邻接矩阵,由此从各个维度都可以判断两人之间的上下位关系,就亲属关系来讲是一个回路,他们俩是同一层次的。接着后续的处理就是跟求平均数一样,每个维度设定一个权重。根据ISM各个维度的结果求个平均数就行了。
拉登的这个例子,刨除搞笑的情况,实际上它的分析方法还是有新意的,就是用了各个维度上分别建立一个ISM的模型。这种从研究方法上可以说上一些。
大部分的文章是三段式,先介绍一下研究的东西,然后就是从建立可达矩阵到出层级图的一堆过程。接着就是解释这张图的意思。会说跟会写的,能写得妙笔生花。而笔头不行的人,一般有这么一个套话:“根据图层我们可知,最下一层要素$\{X,Y,Z\}$是根本原因,往上是表层原因。”这种表述不能说错,几乎所有的文章都是这么表述的。但是这种解释并不确切,或者说不完备与不严谨。
其实,最下一层是根本原因,这个原则并没有错。但是根本原因的要素的性质就是只有输出,没有输入。而轮换法或者原因优先的方法,会把系统中所有只有输出的要素都放置到最下面一层。而按照经典方法得出的层级图则不是。如果用轮换法或者原因优先抽取规则一下就有新意了。并且可以怼一堆人。
如果是体力派的,就直接贴几种层级图出来,然后对比一下,就更能说明问题。
用原因优先的方法建模是采用了新的规则,用了新的更合理的规则当然是有新意了。
为了更好的理解轮换法,轮换法的优点,我们先来看一个例子。
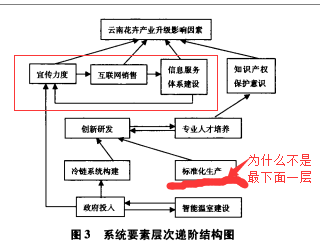
上图是一个典型的ISM层级图,且是用经典的结果优先抽取规则得到的层级图。为了对结果进行解释,一般都是教条的,可以不动脑子的解释着,由结果图可知,该系统的根本原因是最下一层要素,即(政府投入+***)。然后吧啦吧啦的说上一堆东西。
问题来了,我们从另外一个角度考虑,即原因的要素是只有输出,没有输入的要素,也就是根本原因的要素应该有三个,{政府投入,智能温室的建设,标准化生产}。那为什么按照经典的层级抽取方法只有两个要素是根本原因层呢?用什么样的抽取方法能做到最下层有三个要素?
答案就是用轮换抽取规则!
如果你用这种方法写文章,一下子创新点就出来了,而且这种新意是跟人讲道理来的,是不好反驳的。答辩的时候不会有老师问你:你的论文创新点在哪里?最多会说,创新点不足。当然可能会有一些功力比较低的老师问,你这个方法比经典的方法好在哪里?如果有老师这么问,一般来说是你论文没有写清楚,当然不排斥,老师没有看懂,毕竟很多老师的特长在不同的地方,这么问也很正常。尽管这种轮换法会怼上几乎所有的按照套路来的ISM的分层方法,但是原来的方法就是不严谨,不那么合理。轮换法就是更合理,这个是经得起推敲与严格的数理逻辑检验的!
比较有意思的是,有一些人准备用这种方法,他首先是问我,这个方法有没有别的文章写过呀?我说应该没有,我又不搞学术,你就用上去呗。然后这个小姐姐来了一句,哇,别人没有写的我不敢用。当时差点没把我气得吐血。而到后来我发现有这个想法的还真不是一两个人,而是一批人。不乏一些博士生,而且还有一个居然是计算机系的博士生,实在让人吐血。说白了这些人就是不习惯独立思考,喜欢文献里抄来抄去,或者是做作业一样,哪怕是一丝丝另外的角度考察问题都不肯。当然,对于非计算机系的还可以理解,毕竟矩阵呀什么的不大好学,没有权威的文献,或者是自己完全理解的前提下,的确不大敢用!但是对于那个计算机系的博士,我到现在都理解不了。也许是他觉得这种方法本身就挺low的吧。
ISM建模的根本两个假设是,第一、系统由要素组成;第二、要素之间的关系是确定的有一条带箭头的线或者没有带箭头的线。
仅仅从第二个假设出发,就能弄出很多新东西出来。
※ 多维度下的解释结构模型
上面拉登的例子就是多维度下的解释结构模型,它就是改变了一个假设,要素之间的关系,不是只有一条箭头,而是有若干个带颜色的箭头,要么有,要么没有。而到了ISM这块其实很简单,无非是多算几个而已。多输入几个矩阵就行,反正算这个东西不是事!
※ 模糊解释结构模型
模糊解释结构模型它改变的假设是,要素之间的关系,只有一条箭头,而这个箭头在1的时候是完全清楚的,在0的时候就没有这个箭头。至于如何定义清楚跟不清楚,就需要学习一下模糊数学的基本知识,不要把它简单化。简言之,如果是利用最大最小模糊算子的运算规则,模糊解释结构模型的标准过程且计算量最小的为:求出模糊可达矩阵,算出模糊可达矩阵中有多少种值也就是阈值集合,根据这些阈值,分别对原始模糊矩阵取截矩阵。此时的截矩阵就是个布尔矩阵。剩下的就是ISM模型的方法了。而现在很多文章直接来一个四舍五入的截矩阵,这种纯属脱下裤子放屁多此一举。
※ 不确定性解释结构模型
这个模型很简单,就是认为某几个要素之间的箭头,有时候有,有时候没有。然后一个不确定的值对应2个矩阵,n个则对应$2^n$个矩阵。然后对$2^n$个不同的邻接矩阵分别求出可达矩阵。大多数情况可达矩阵只有有限的几个,然后对有限的可达矩阵再分层,接着可以比较有限的几个结构的异同。这种对于不确定的值限定在6个以下即可。具体的运算过程可以看不确定解释结构模型。
我喜欢推荐这个用这个方法,理由为:
第一、它符合实际分析的状态,而不是跟ISM一样,强行把没有把握的值捣鼓成0或者1。
第二、可以理解等可达的概念。
第三、几乎没有人去专门命名这个方法,自己可以取很多高大上的名字,比如量子纠缠等等时髦的名词,就看你敢不敢往上堆。
第四、能体现你的苦力活和工作量,$2^n$本身就是一个天文数字的计算量,比如$50\times 50$的矩阵中间有6个不确定的值,也就是对一个大矩阵算64次。
※ 时序解释结构模型或者条件状态解释结构模型
这个模型很好理解,就是认为某个时间状态某几个要素之间的箭头,有变化。比如事件开始前是一个邻接矩阵,事件结束后的时间是另外一个邻接矩阵。然后对这么几个时间或者状态对应的结构画出来。
这种就是同一个ISM方法做几次的意思,项目类型用这个分析很有有用,比如项目风险,就可以分时间段,或者是公司的状态段来解释。
※ 共轭解释结构模型
这个模型可以尝试下,共轭的概念来自化学学科里面的共轭结构的概念引申到ISM中来其最简单的形式如下。
$\{S_i, S_j, S_k\}$
$$a_{ij}= \begin{cases} 1, \text{当 $a_{jk} =0$} \\ 0, \text{当 $a_{jk} =1$}\end{cases} $$这种情况很常见,就是一个要素A直达X要素后,A到Y的值就为零。也就是一个要素是另外一个原因就不是另外一个要素的原因了。这种其实是关系之间的互相制约。
写这篇口水文的起因有很多,这些缘由是跟很多用ISM方法写作业或者写论文的人交流之时自然而然产生的。而让我感触最深的是一类叫勤奋的没有质量的思考者的提问。这类人或多或少存在着一个很不好的现象,认人不认理,没有自信。比如这堆人经常这么问:“我看了好多文章,怎么我照着你网上的方法跟我手算的是一样的,但是跟别人的文章不同。”
我随口丢过去一句:“论文错的多了去了,我以前核验过大概是有三分之二。”
然后这伙人还是不听劝,又去按照教材的模式,照猫画虎,依葫芦画瓢的方式做下来。
这类属于劣质的勤奋者,有一些则是压根不思考,也不勤奋,属于像素级的模仿者。
像素级的模仿者,跟抄袭差不多,就是照抄教材的,一般教材的要素不多,然后他分析的问题跟教材的一样,比如教材是6个要素,它的也是6个要素。教材为了说明问题,有的会有不连通的两块,他们是完全照抄邻接矩阵,改的就是要素的名称,计算过程也一样,他们变动的无非是把可达矩阵R改成了M,把要素的名称自己原来用S1表示,他用F1表示。最后连解释也是抄的。
喜欢照搬教材模式太多了,所以很多学校与杂志社会强调查重率与新意!于是很多人成了体力派,使劲的堆砌要素,他们把堆砌体力变成了新意。比如我所说的那个56个民族56朵花的那哥们。比这个哥们更有体力的也有,找我最多的是64个要素,当然公交换乘系统的不算,它是3000个要素,属于算法层次的交流。
想了解用ISM方法的错误比例是最主要的原因,同时想了解要素个数平均值有多大也是一个重要原因,根据期刊的要素数目,我调整网站上的要素数目输入的最大值,这样可以遏制体力派人士的蔓延。另外一个是看有多少用传统的方法。很遗憾,这个不用看都知道!
当然我是个写程序的人。不可能一个敲入矩阵验算的。所以我是先用个文本识别的工具先识别矩阵的截图,然后目测核对一下。但是这个识别程序比较搓,最大的问题是会把1识别成l把0识别成O。
判断对错的方法,上面ISM层级图的建构讲了,如果认真看完下面100篇的核对与分析肯定可以发现我的方法。
结论就是:51%的错误率
详情见表格:
想在线计算解释结构模型的或者直接生成论文的请发电子邮件到, hwstu #sohu.com 把#替换成 @